GSoC 24 | AI-Generated Choreography: from Solos to Duets
Hello guys! In this summer, I had the amazing opportunity to participate in Google Summer of Code 2024, contributing to the AI-Generated Choreography: from Solos to Duets project at HumanAI. This project focuses on leveraging cutting-edge AI technologies to innovate the way choreographies are created, focusing particularly on duets. You can find more about my role in this project on my Contributor Profile of GSoC.
In this blog post, I’m excited to take you through the details of our network pipeline. All the code is available on Github. For a hands-on experience, dive into my Google Colab Notebook which provides an interactive demonstration of the network.
Before diving into the technical details, I want to express my heartfelt thank you to my incredible mentors Mariel Pettee and Ilya Vidrin for their incredible guidance, and my colleague, Luis Zerkowski, for his collaborative efforts and insights from his project.
Now, let’s get started on our journey through the exciting world of AI-generated choreography!
What’s this project about?
This project aims at developing AI-generated choreography for duets. It outlines a novel approach leveraging Transformer and Variational Autoencoder to analyze and generate dance movements, focusing on creating authentic dance material that reflect the intricate dynamics between dancers.
Transformers are advanced machine learning models that use attention mechanisms to process sequence data efficiently. They focus on relationships between all parts of the sequence simultaneously, making them faster and more effective at capturing complex patterns than traditional models like RNNs.
Meanwhile, Variational Autoencoders are generative models that learn to encode data into a compressed latent space and then decode it back to the original space. They balance a reconstruction loss, ensuring data similarity, with a KL divergence loss, promoting distributional similarity to a prior, facilitating data generation and representation learning.
We aim to utilize both models to generate sequential dancing data by taking advantage of attention mechanism and probabilistic generative capabilities. This integrated approach allows the model to not only understand the complex patterns in dance but also to innovate by generating movements that maintain the fluidity and expressiveness essential to human-like dance performances.
Solution Approach
Overall, the project uses Probability-and-Attention-based Variational Autoencoder to generate dancing data. Here’s an overview of our strategic methodology:
Firstly, we dive deep into understanding the essential relationships between different body parts of individual dancers. This is achieved through a specialized VAE that incorporates self-attention layers alongside LSTM layers, allowing the model to recognize and model complex interdependencies within the movements of each dancer.
Building on this, we develop a Duet VAE specifically designed to comprehend and model the interactions between two dancers. This component of our solution is crucial for generating choreography that accurately reflects the cooperative nature of duet performances.
To ensure the focus remains on accurately reconstructing dancer movements, we introduce a probability-based method. This technique selectively prioritizes the reconstruction accuracy of the dancers’ data, ensuring that the model’s learning is concentrated on the most relevant aspects of the dance.
Furthermore, to augment the continuity of the generated choreography, we implement additional losses such as velocity loss. These enhancements help in refining the smoothness and temporal coherence of the dance sequences.
Our deliverables are comprehensive and aimed at pushing the boundaries of what’s possible with AI in performing arts:
- We have constructed a dataset consisting of point-cloud data, which encapsulates the motion capture poses from various dance duet videos. This dataset forms the backbone of our training and testing phases.
- The model is able to generate the movements of Dancer #2 conditioned on the inputs of Dancer #1.
- We will collaborate with the original dancers to use the model outputs to inspire new performance material.
Pipeline
1. Dataset Preparation
Firstly, I would like to express my gratitude to Ilya for providing exceptional videos of duet performances :).
High-quality training data is essential for an AI model. In order to extract 3D joints (point cloud) data from videos provided by Ilya, we have tested two open-source tools for pose estimation, OpenPose and AlphaPose.
We had no luck in managing configuration of OpenPose, so we switched to AlphaPose, which provided many different kinds of models for both 2D and 3D inference. For 3D inference, AlphaPose utilizes Hybrik and YOLO for body detection.
AlphaPose provides so many different models trained on different datasets. The image below shows the 136 keypoints extraction result using this model.

For body mesh detection, AlphaPose uses SMPL.

Finally, we ended up with using Hybrik to extract 29 body joints for every dancer, optimizing our dataset for further analysis. The workflow is like this:
- Use YOLO to detect body instances in the frame
- Pass results (boxes) from YOLO and original image to the Simple3DPoseBaseSMPLCam model
- Get the inference result of 3D joints, then move the first joint to
(0, 0, 0)
Therefore, in order to keep the interaction between the dancers, we remove this line in the model forward pass.
Installation of AlphaPose might be a little tricky. Please make sure that you have available GPU resources. It’s very hard to use AlphaPose with CPU because it uses CUDA operators.
We also conducted thorough preprocessing of the data to ensure its quality and consistency. This included addressing issues such as missing frames, frames that captured only one dancer, index mismatches, and jitter. Each step was crucial to refine the raw data into a usable format for our analysis. Below is a clip demonstrating the final processed data, showcasing the effectiveness of our preprocessing steps:
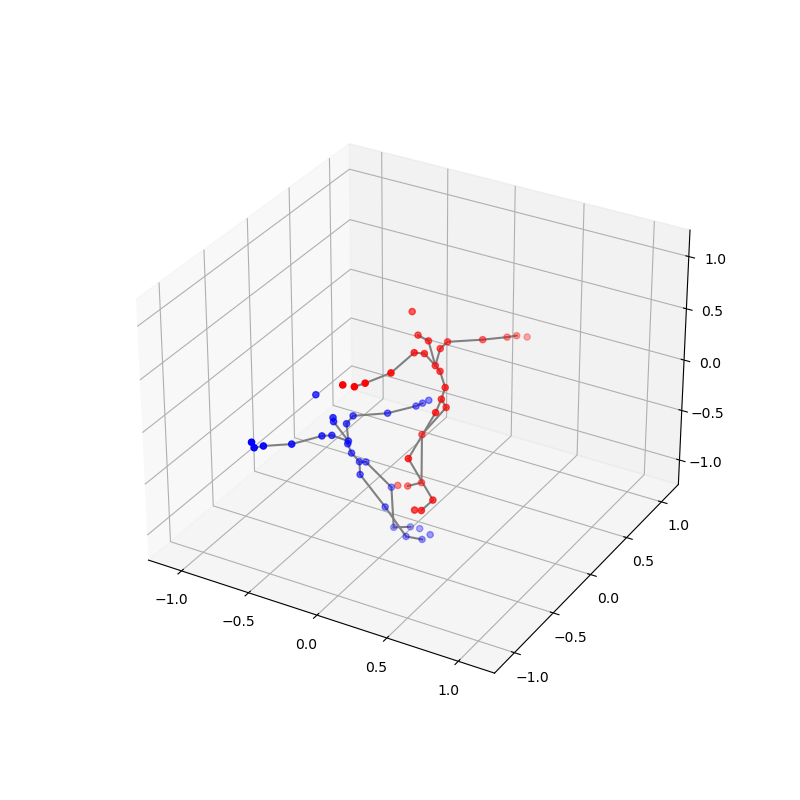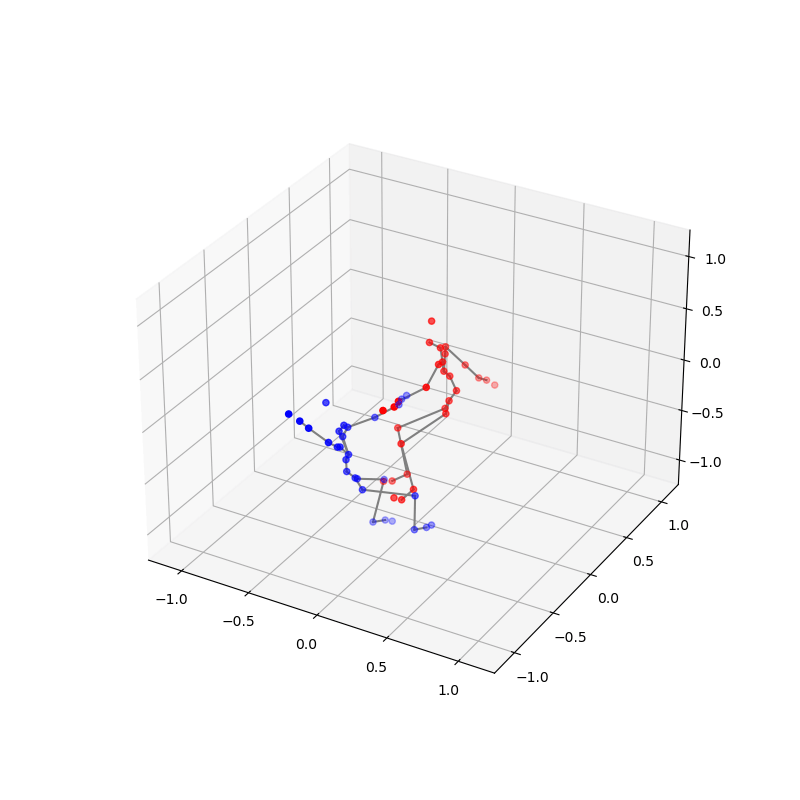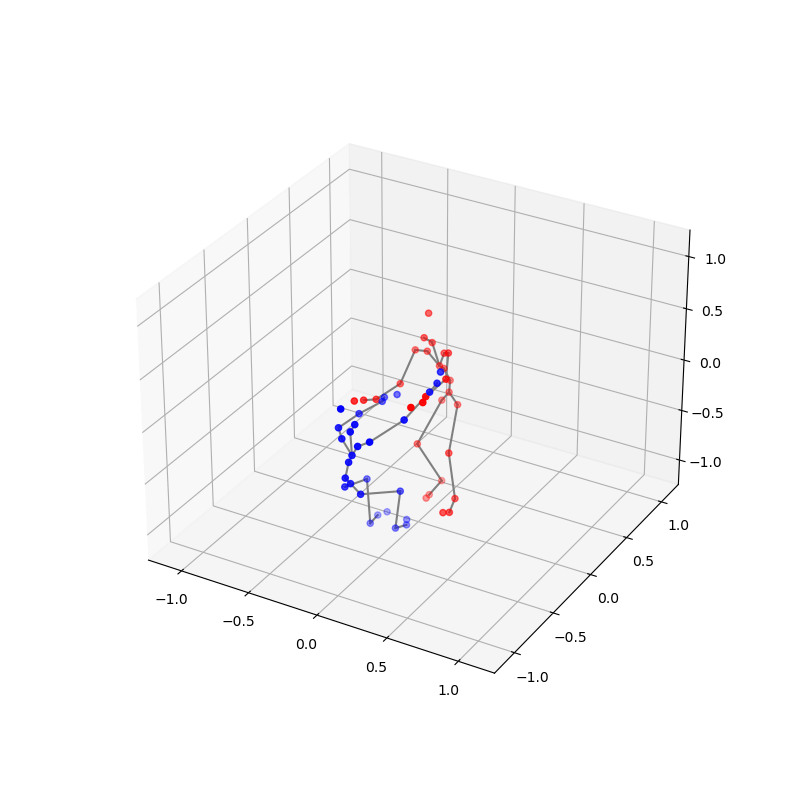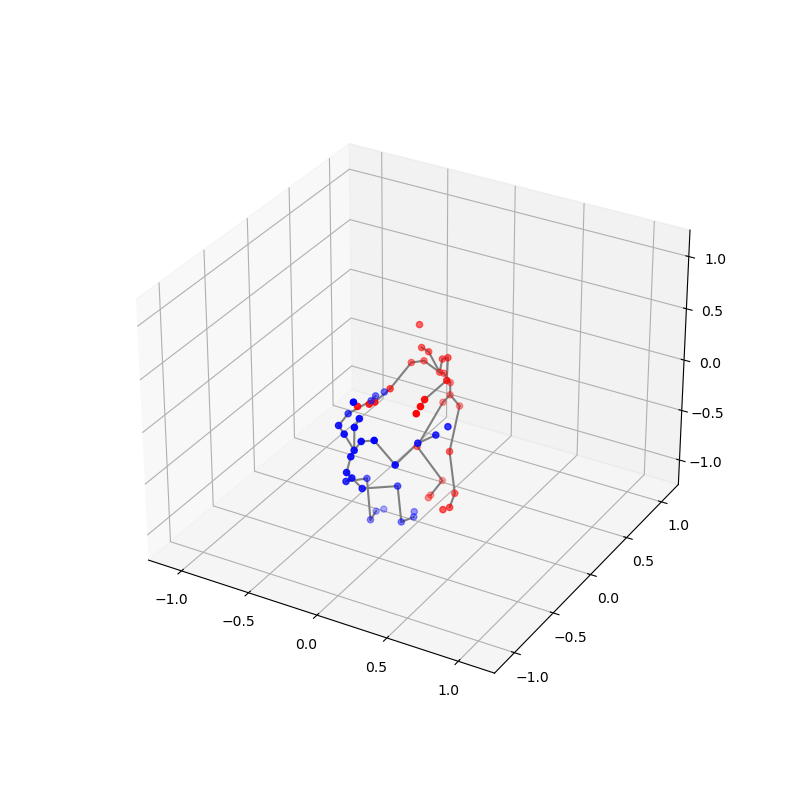
2. Probability-and-Attention-based VAE for Duet Generation
2.1 Motivation
As we have stated before, the transformer’s ability to model interactions between sequence elements at different positions allows us to capture the dynamic interplay between dancers’ movements over time. On the other hand, the variational autoencoder (VAE) will enable us to generate new dance sequences that are both diverse and realistic by learning a latent space representation of dance movements. We believe the combination of these two models would be effective to complete the ChoreoAI task.
2.2 Network Design
The network consists of three VAEs designated as VAE 1, VAE 2, and VAE 3. Each VAE processes different aspects of dance movement sequences, with VAE 1 and VAE 2 handling individual sequences and VAE 3 focusing on the absolute distances between dancers, capturing their spatial interactions.
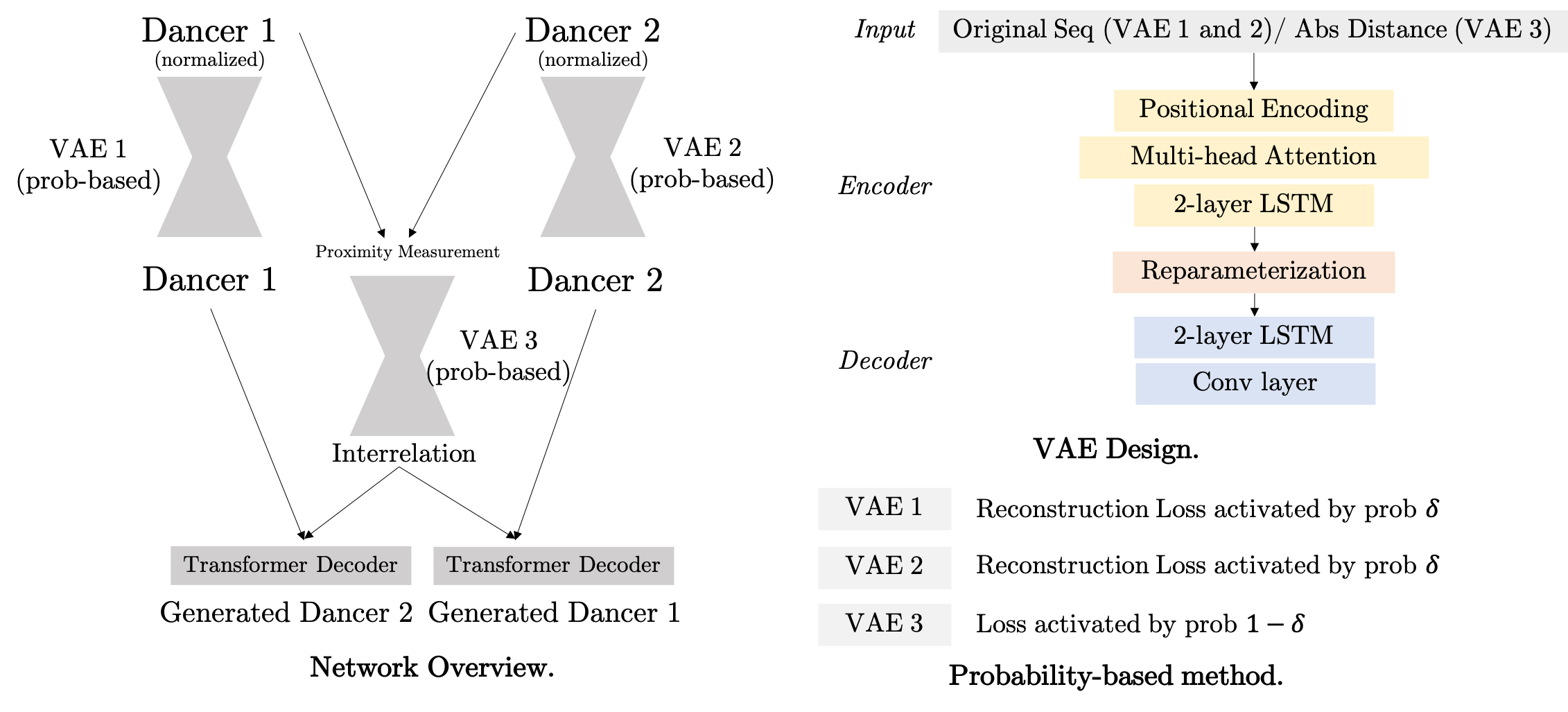
2.2.1 Input and Output
- Input: Sequences for dancer 1 and dancer 2, with shape
[seq_length, num_joints, dim], the time window for this sequence is[t, t + seq_length]. - Output: Predicted sequence in the next time step with same shape as input
[seq_length, num_joints, dim], and the time window is[t + 1, t + 1 + seq_length].
2.2.2 VAE
- Positional Encoding: This component is crucial as it provides the model with information about the sequence order of the dance movements, which is essential for understanding the temporal dynamics of the dance.
- Multi-head Attention: It enables the model to focus on different parts of the dance sequence simultaneously, improving the ability to model complex dependencies.
- 2-layer LSTM: These layers are part of the VAEs’ encoders and decoders, helping to capture the temporal dependencies and nuances in dance movements over time.
- Reparameterization: This step in the VAEs allows for generating new dance sequences by sampling from the learned distribution in the latent space, ensuring variability and creativity in generated dance movements.
- Conv layer: A convolutional layer in the decoder helps to smooth the output from the encoder, an important aspect of performances.
2.2.3 Transformer Decoder for Data Generation
We utilize standard transformer decoder to generate data based on both its own input sequence and context provided by three VAEs. In the forward pass of this module,
- The input sequence is reshaped and processed through the linear transformation to match the expected dimensionality for the transformer layers.
- Positional encodings are added to the transformed input to incorporate temporal information.
- Call the official
nn.TransformerDecoderAPI, withtgtbeing original sequence andmemorybeing the summation of the output from VAE for single dancer and VAE for duet. For example, to generate dancer 2,tgtwould be the original dancer 2 data,memorywould be the summation of VAE 1 output and VAE 3 output. - The output from the transformer decoder is then passed through a final linear layer to ensure it has the correct shape and properties to match the expected output format.
- Finally, the output is reshaped to ensure it matches the original input’s structure.
2.2.4 Original Losses
- MSE Loss: This is a standard loss used to measure the average squared difference between the predicted outputs and the actual target values. It effectively quantifies the accuracy of the model’s predictions by penalizing the error between the predicted and actual dancer positions. MSE is calculated between the Transformer Decoder outputs (predicted dancer movements) and the corresponding targets.
- KL Divergence Loss: This loss component is crucial for the training of VAEs. It measures the difference between the learned distribution (represented by the means and log variances of the latent variables) and the prior distribution, typically assumed to be a standard normal distribution. This loss ensures that the latent space representations do not stray too far from a normal distribution, which helps in regularizing the model and avoiding overfitting. It also facilitates the generation process by ensuring that the latent space has good coverage and that similar inputs lead to similar outputs in a continuous latent space.
2.2.5 Original Model Output Failure Cases
In this original model without any optimization, we actually had several failure cases.
First scenario (in first half both are original data, in second half blue dancer is generated):

We can see the generated data still suffers from jitter. Therefore, we added Velocity Loss to smooth the output. This techniques has been proved pretty effective to improve the performance. However, at the same time, it’s very sensitive to the hyperparameter setting.
Second scenario:
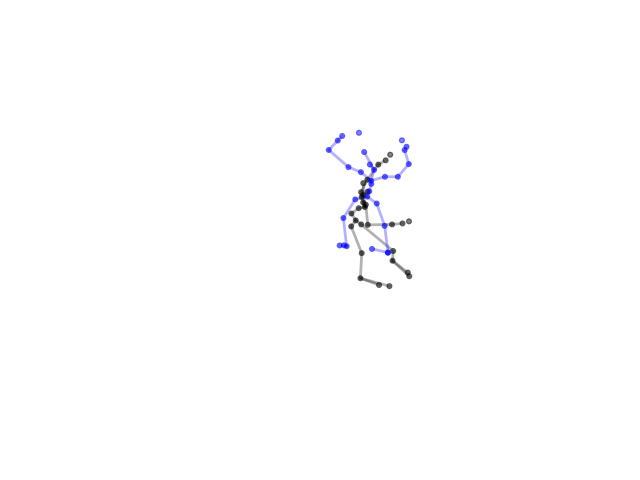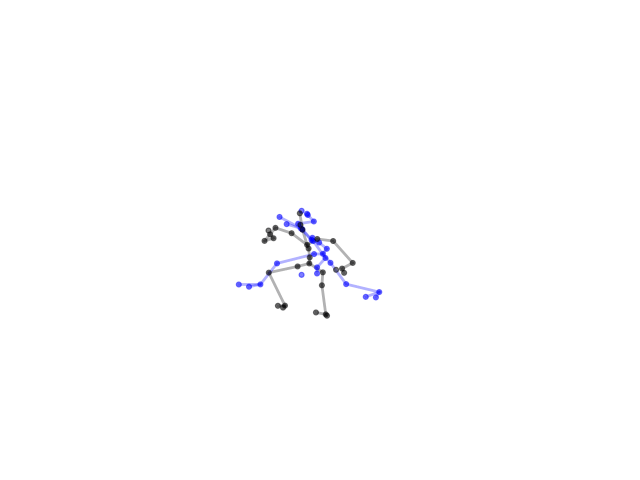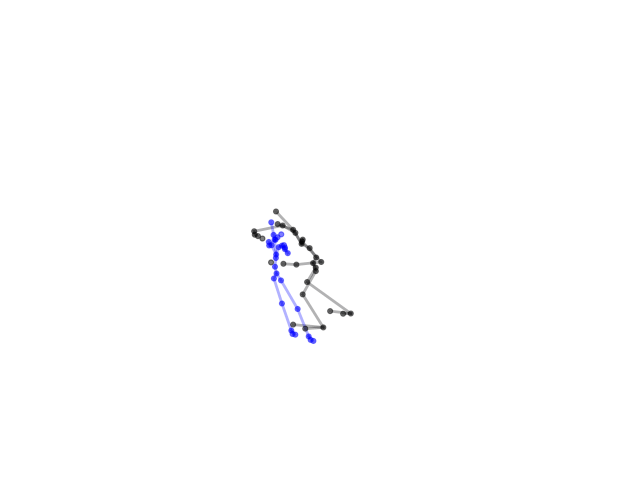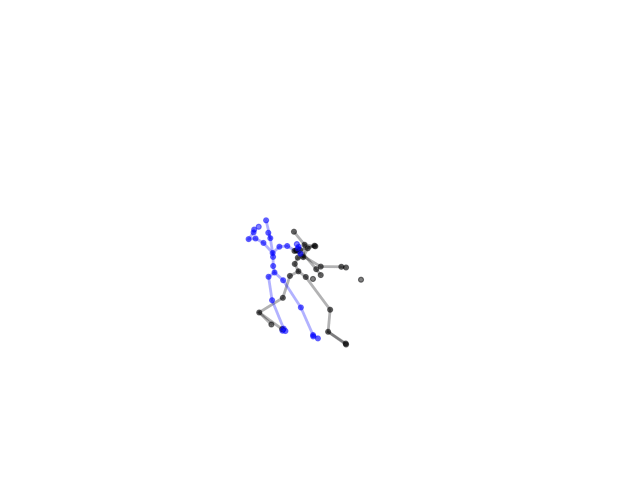

Although we test different data, the output would still have the same pattern. To solve this, we deployed data augmentation technique by adding Gaussian noise to the dataset to increase diversity of samples.
Third scenario:


The network would generate the output deviated much from the original one even though we fed prior distribution of data into the model instead of generating from scratch. To solve this, we designed a probability-based method during training by focusing only on reconstruction performance of VAE under a probability. Details will be demonstrated in the next section.
2.2.6 Probability-based Method
During the experiment, we observed that supervising only the output of the Transformer Decoder resulted in suboptimal reconstruction performance. To enhance the reconstruction accuracy of the individual dancer VAEs, we introduced a probability-based method. This approach selectively optimizes either VAE 1 or VAE 2 with a certain probability, effectively focusing the optimization process on improving the reconstruction loss for single dancers. This strategy ensures that each VAE can learn detailed and accurate representations independently, thereby improving the overall quality of the model’s output.
2.2.7 Velocity Loss
It is designed to maintain the continuity and fluidity of motion between consecutive frames, this loss calculates the first order difference between frames, referred to as velocity, and then measures how much this velocity changes over a specified number of frames (denoted by frames). The loss is computed as the norm of the difference in velocities, which encourages smoother transitions and more realistic motion in the generated dance sequences. In our experiment, Velocity Loss played an important role in regularizing the result to be “rational” and not being crazy. The model also behaves sensitive to the parameters of this loss, including frames and loss_weight.
2.2.8 Learning curves
To get the best model weights, we tested different hyperparameter configurations. Below are training loss and validation loss for 5 configurations for the model, with the best configuration being
linear_num_features = 64
n_head = 8
latent_dim = 64
n_units = 64
seq_len = 64
no_input_prob = 0.1
velocity_loss_weight = 0.05
kl_loss_weight = 0.00005
mse_loss_weight = 0.5
frames = 1
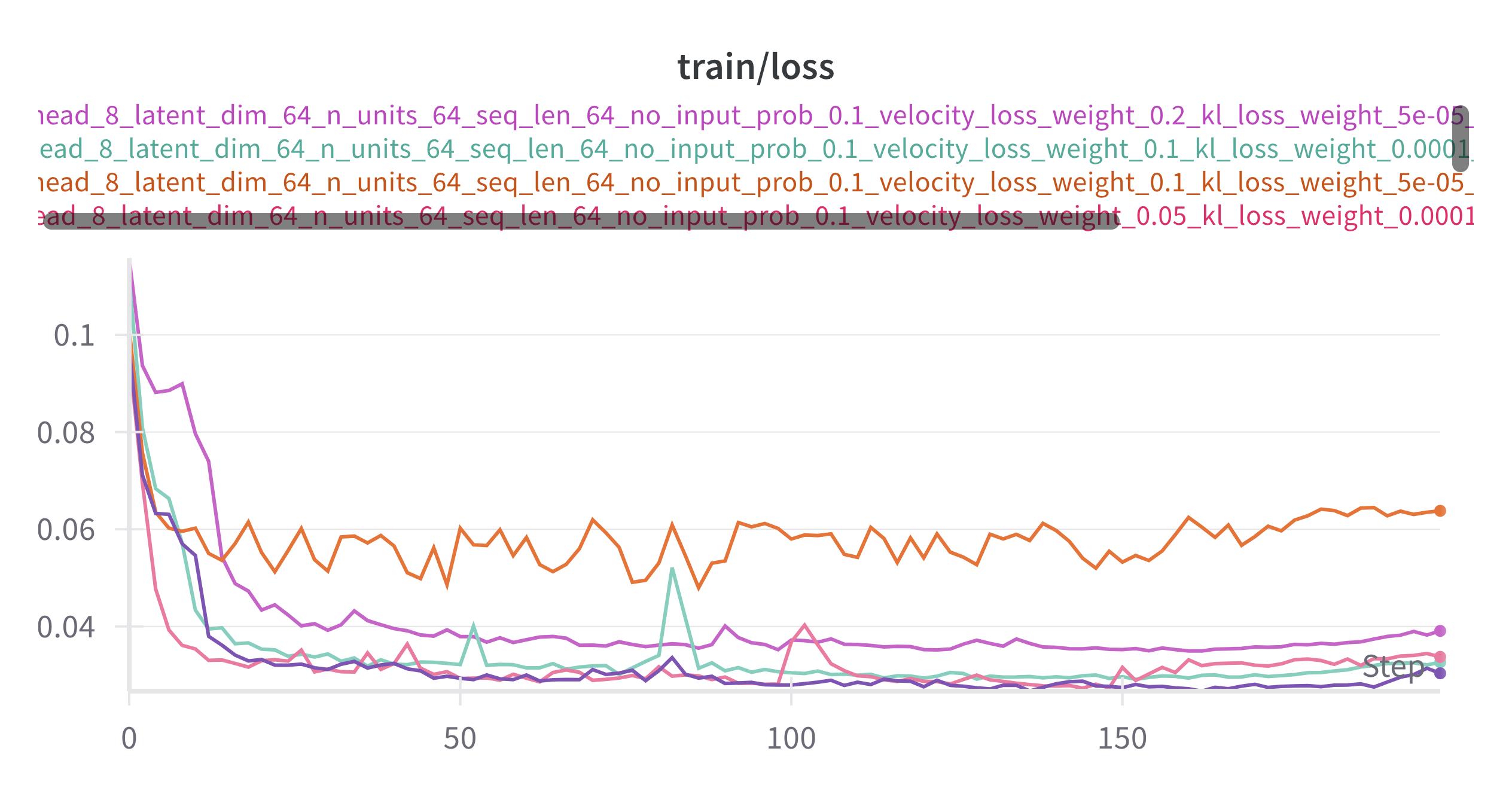
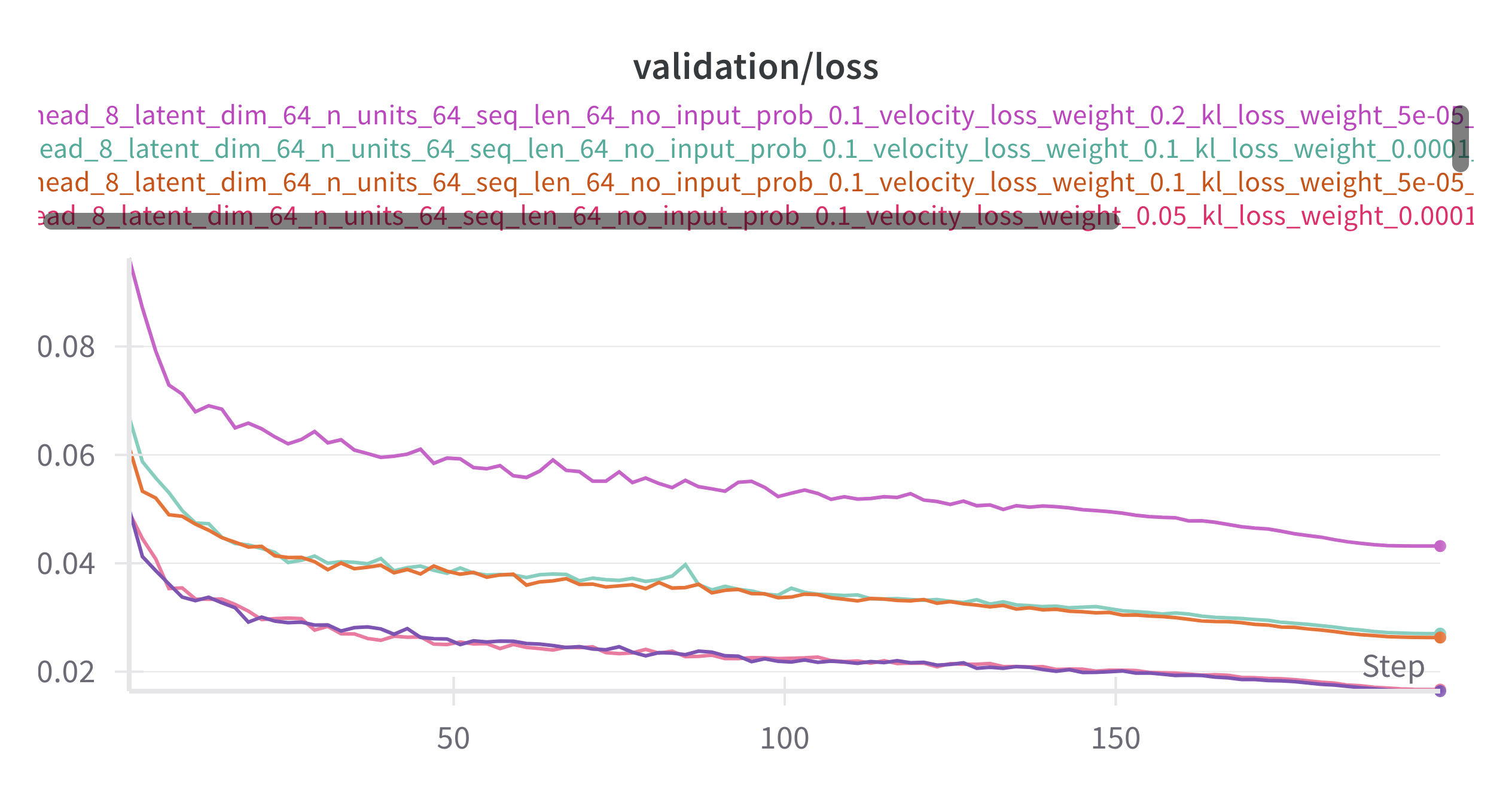
2.2.9 Visualization of Duets
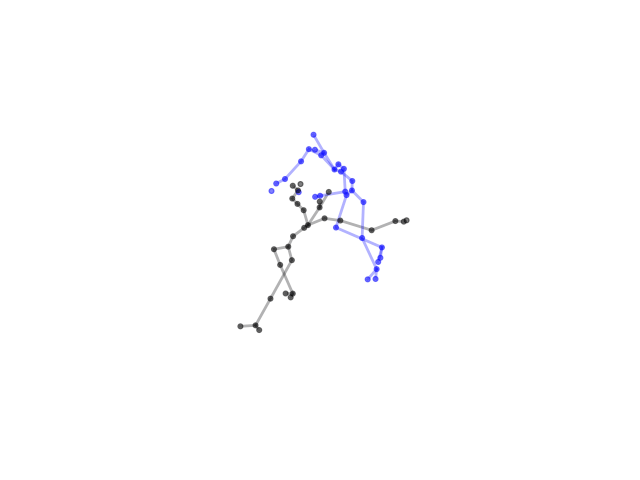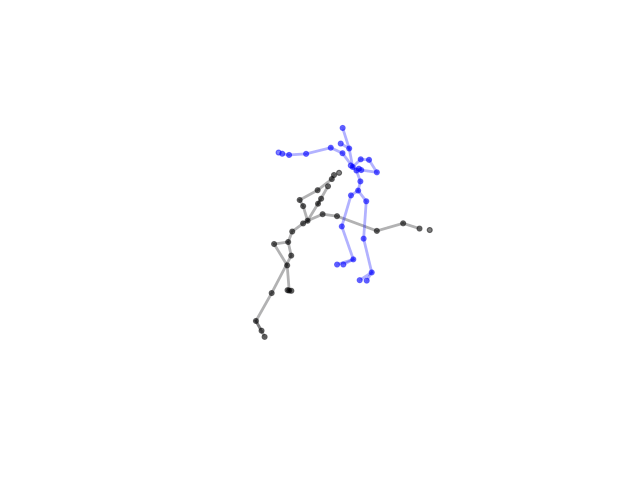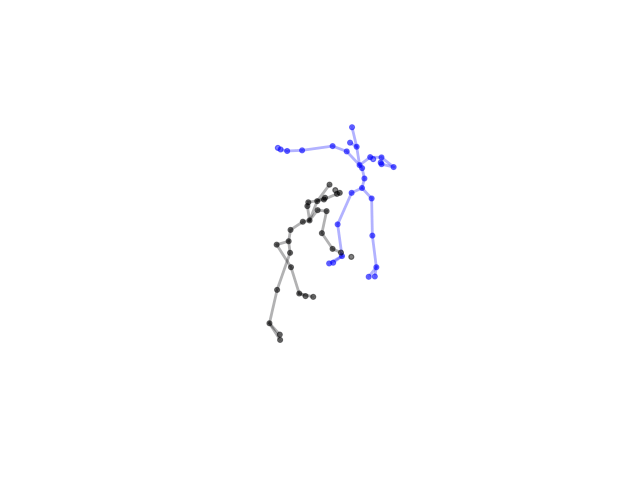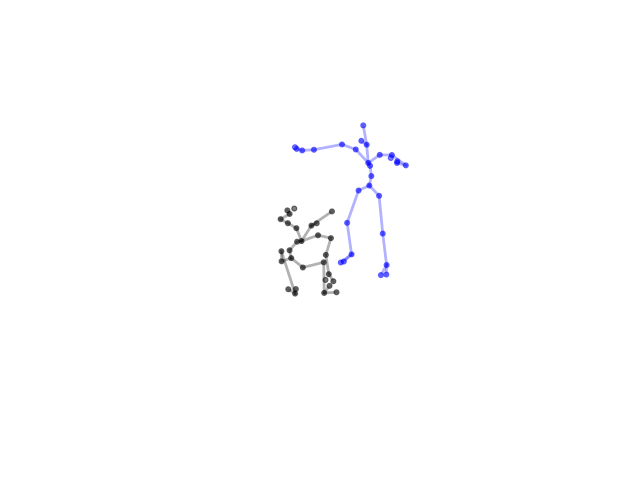
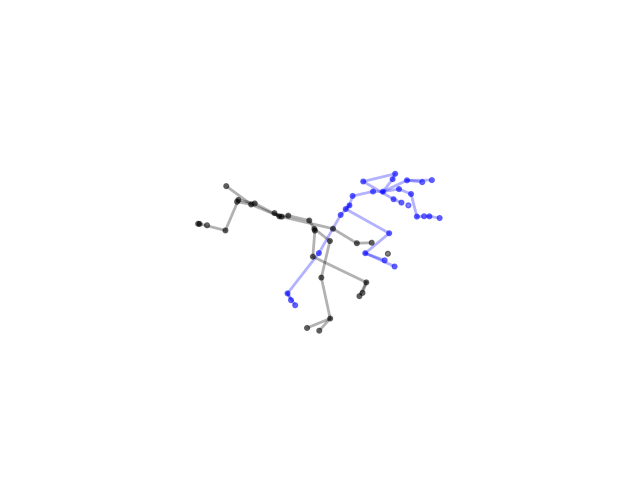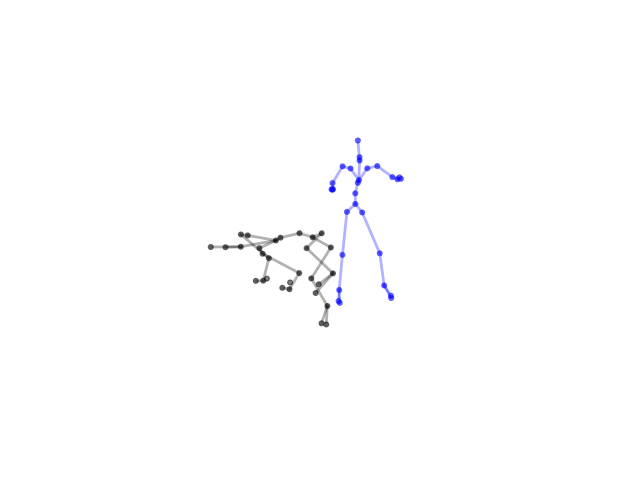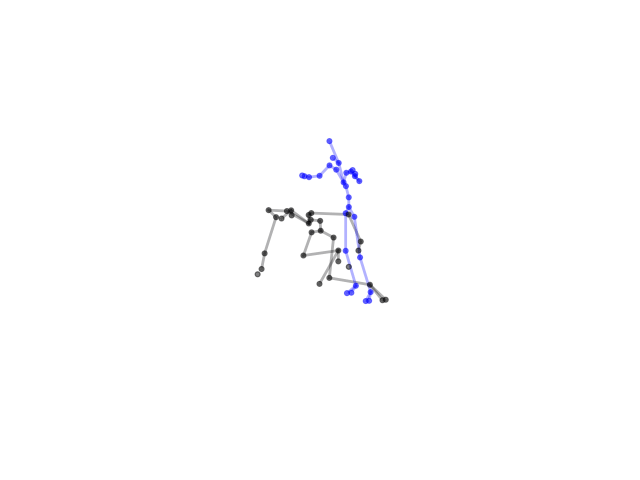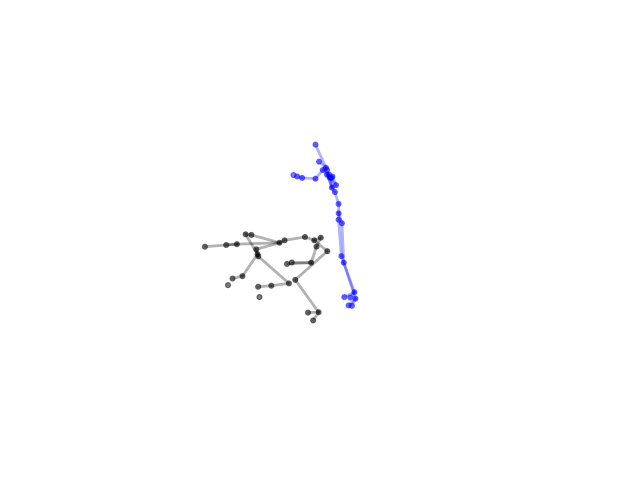
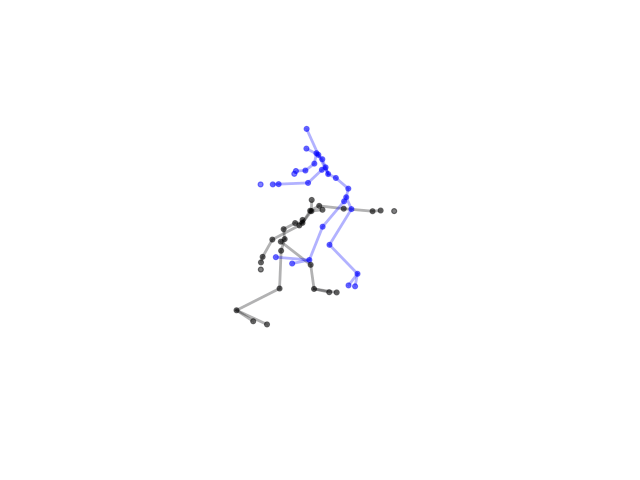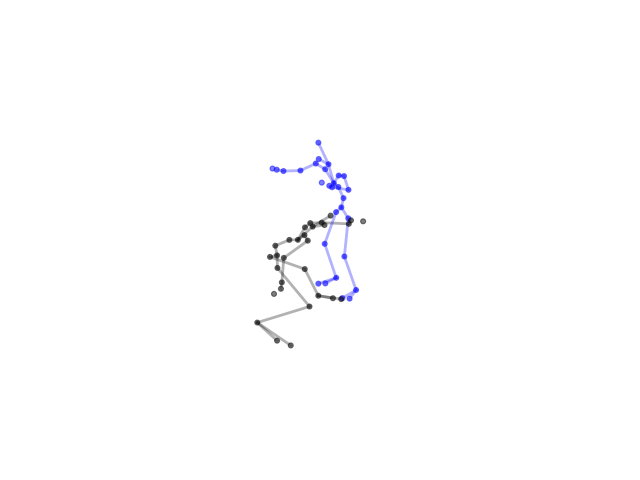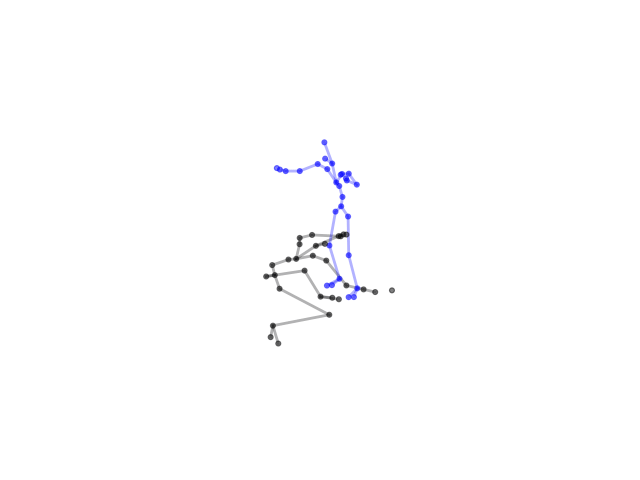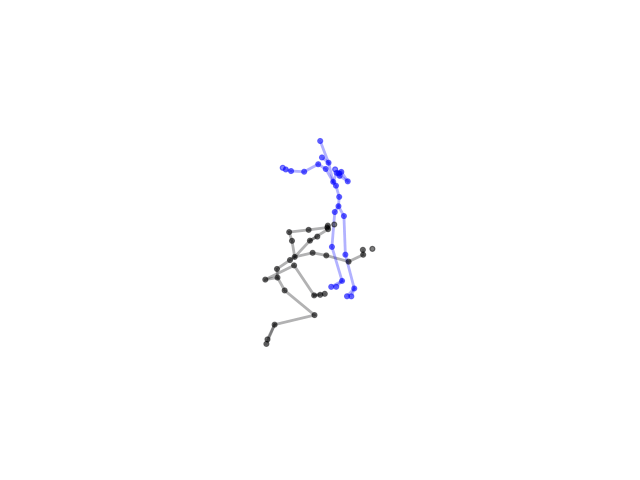
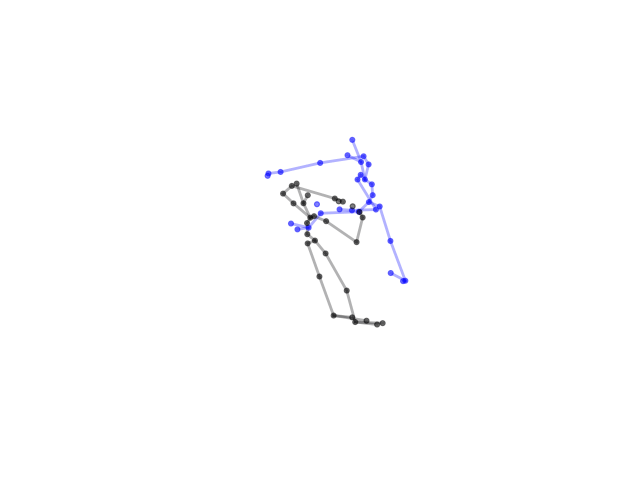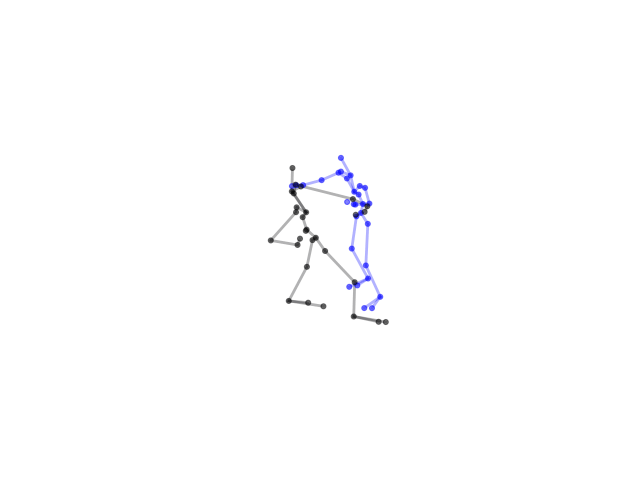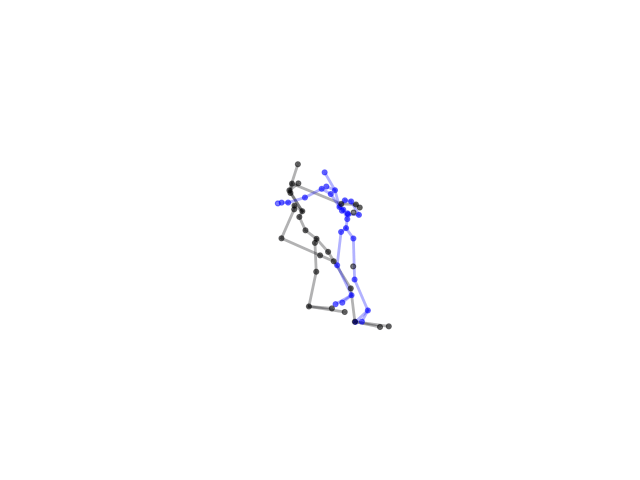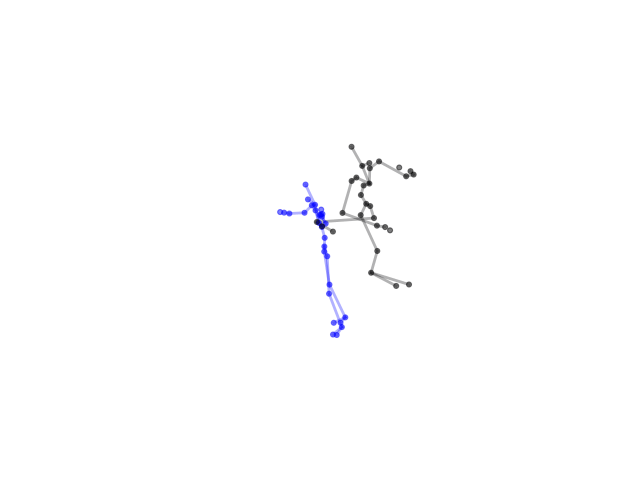
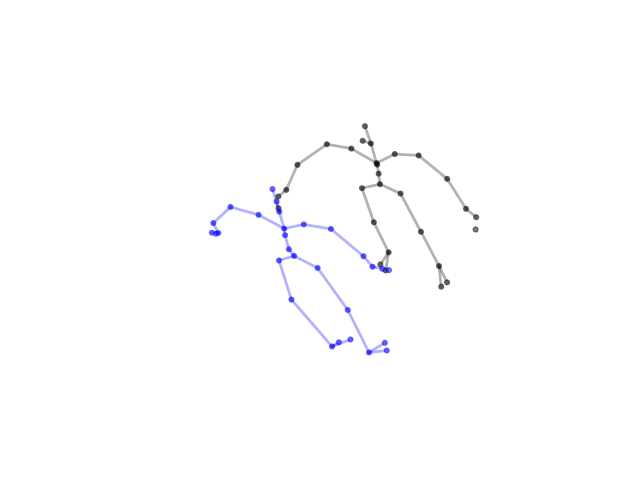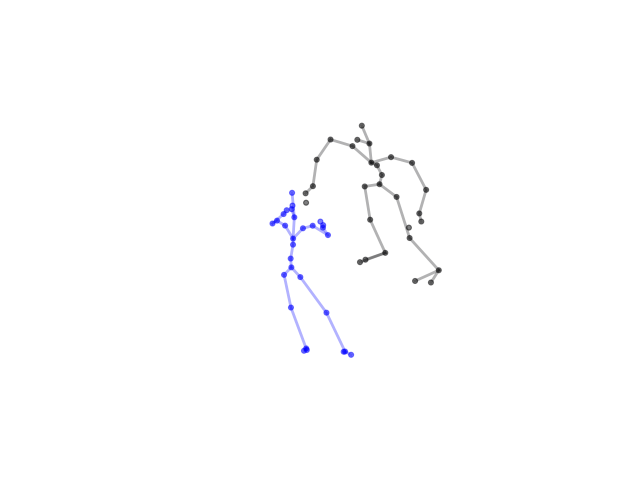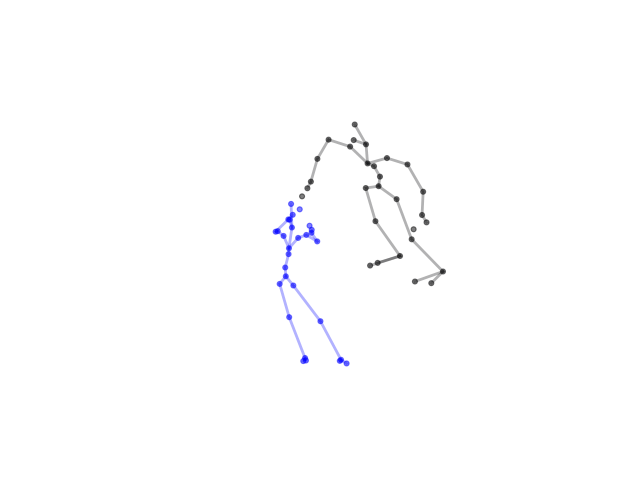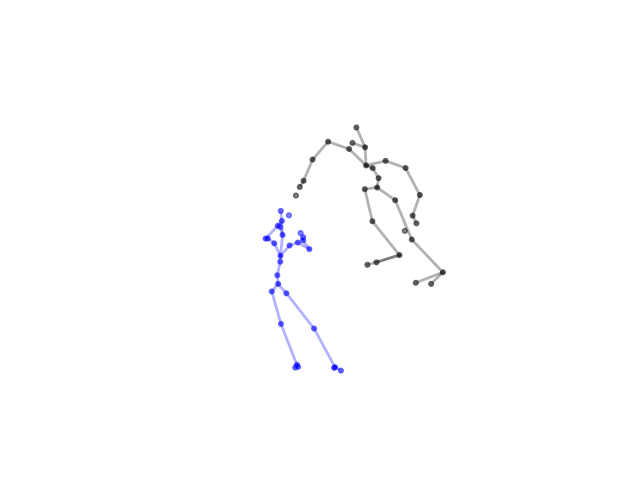
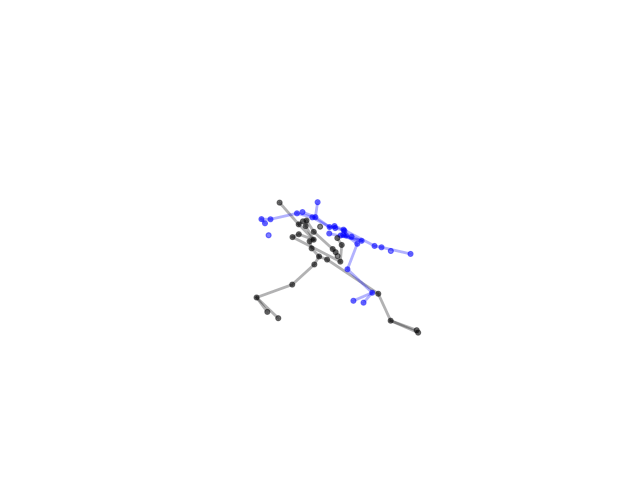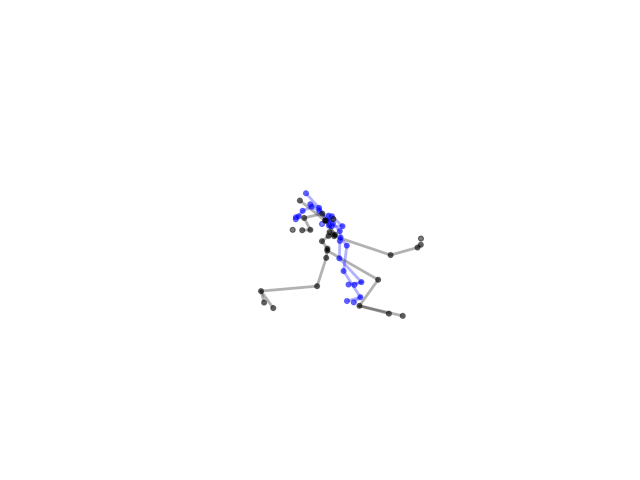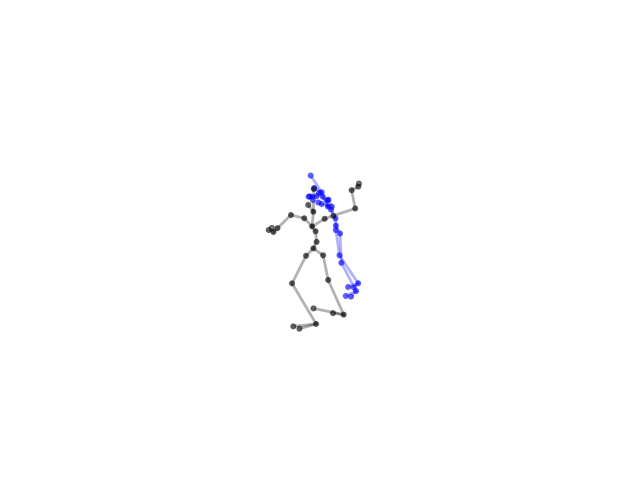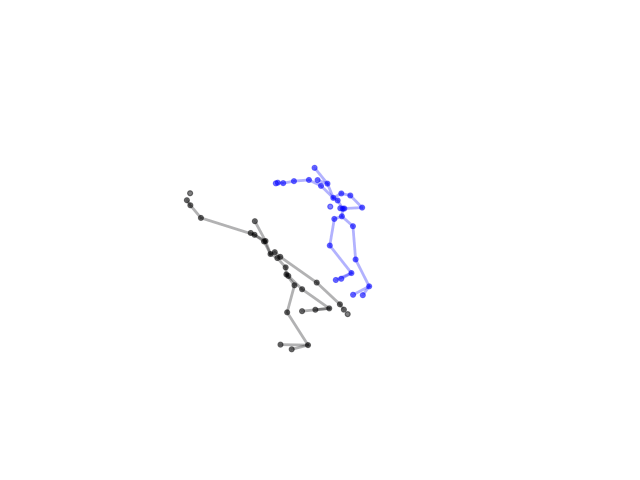
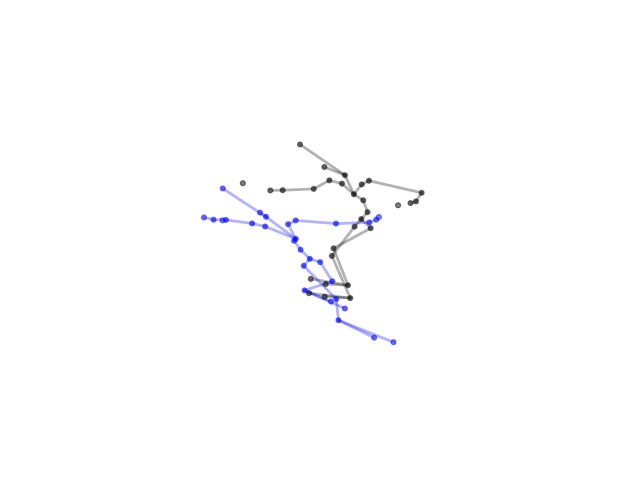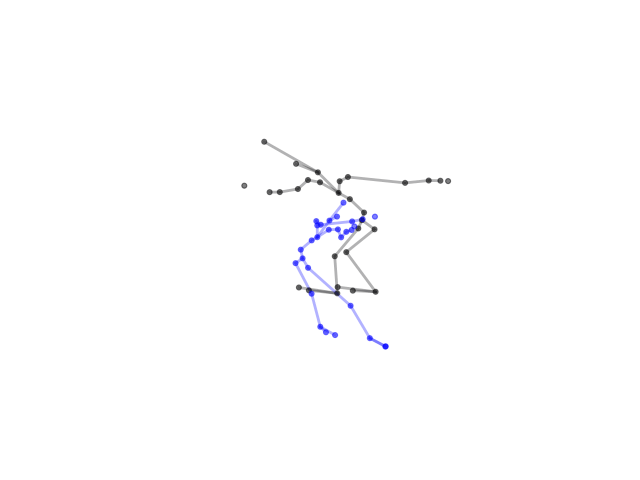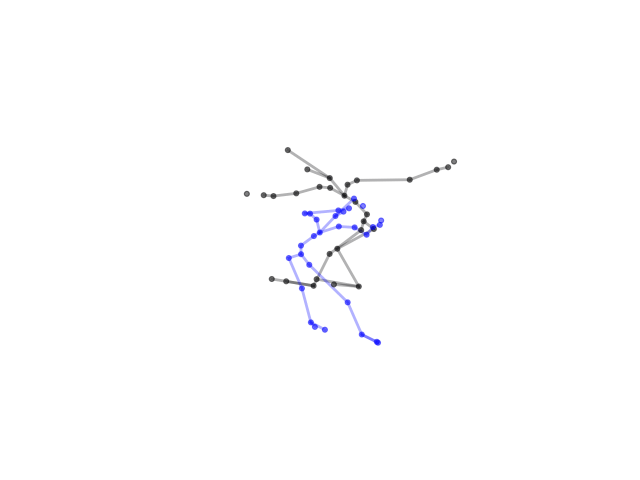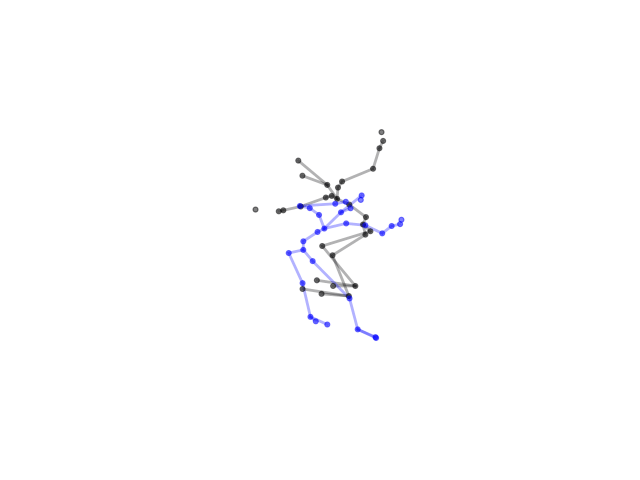
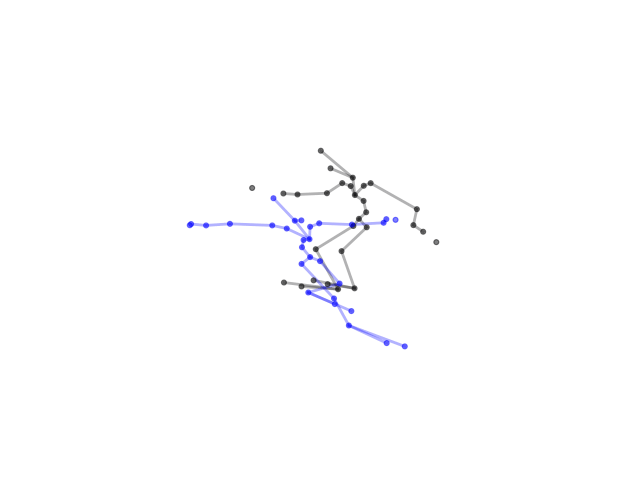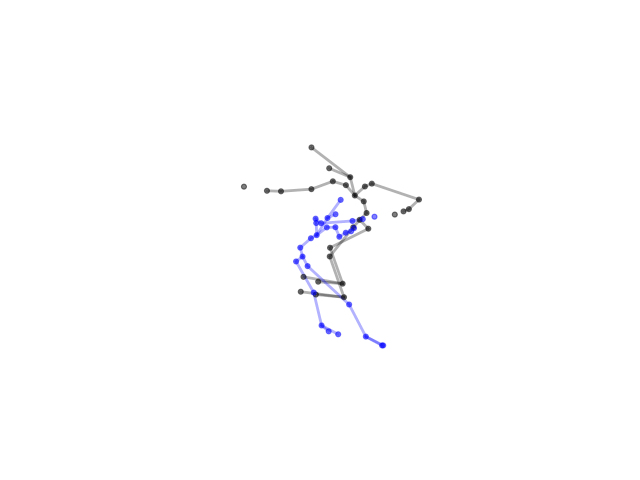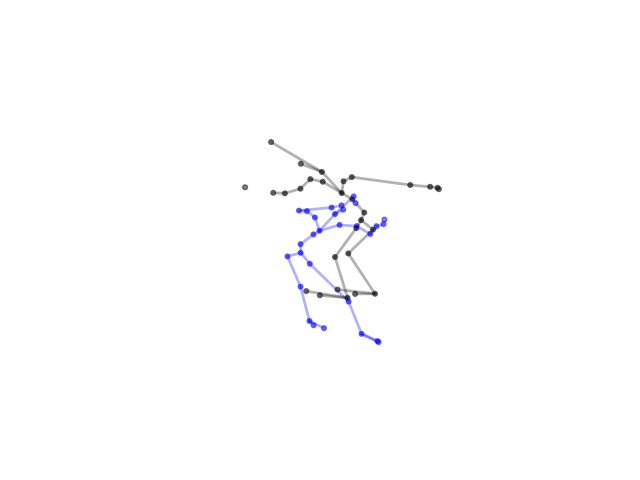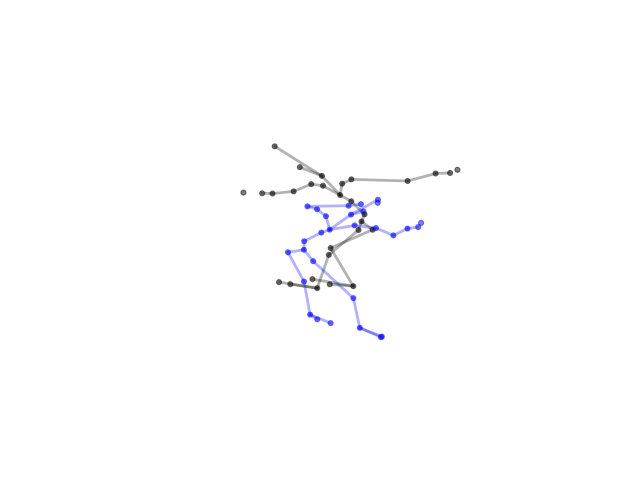
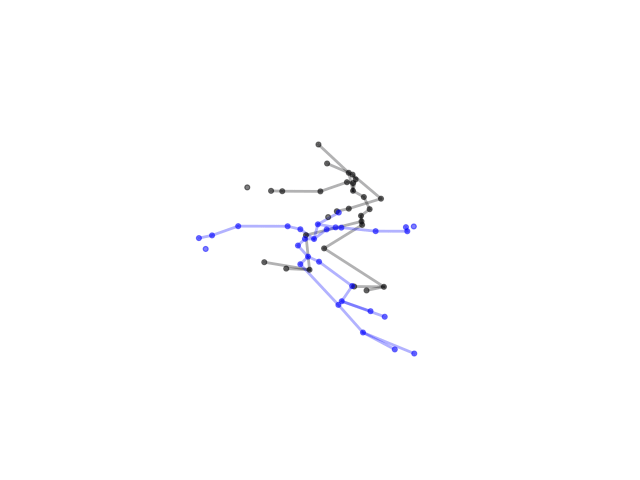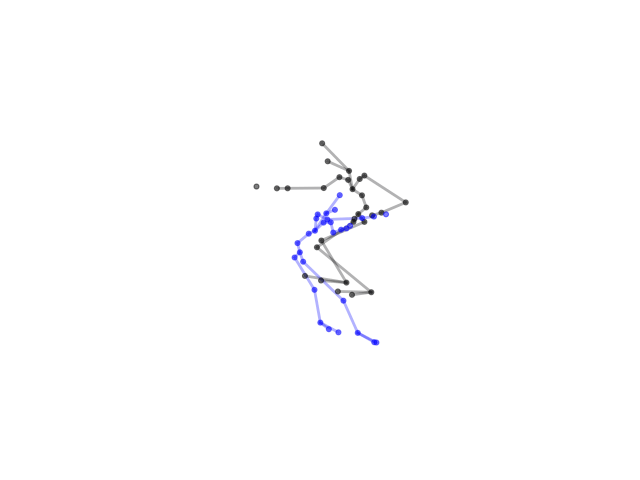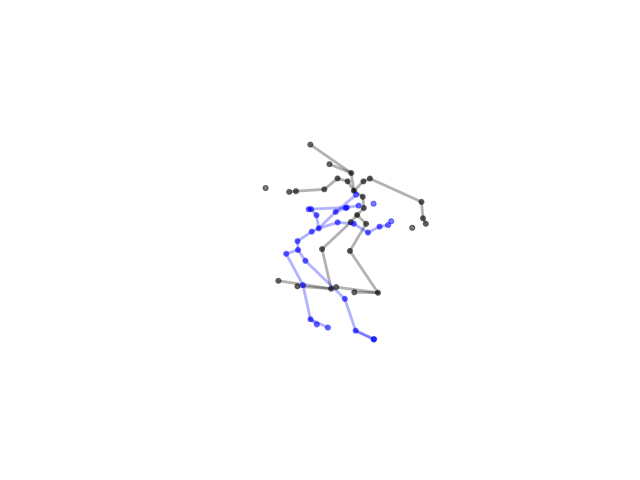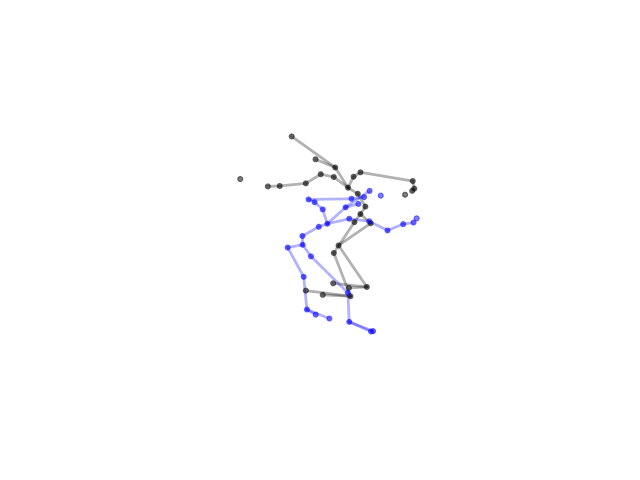
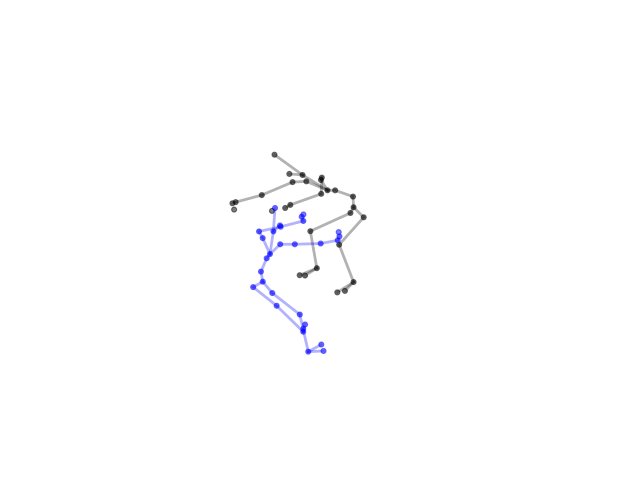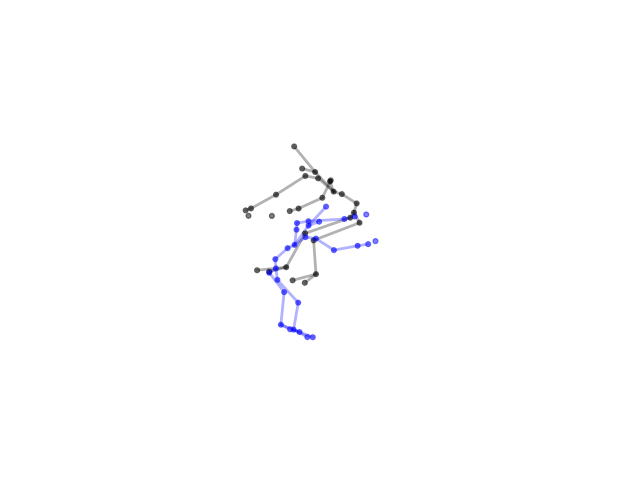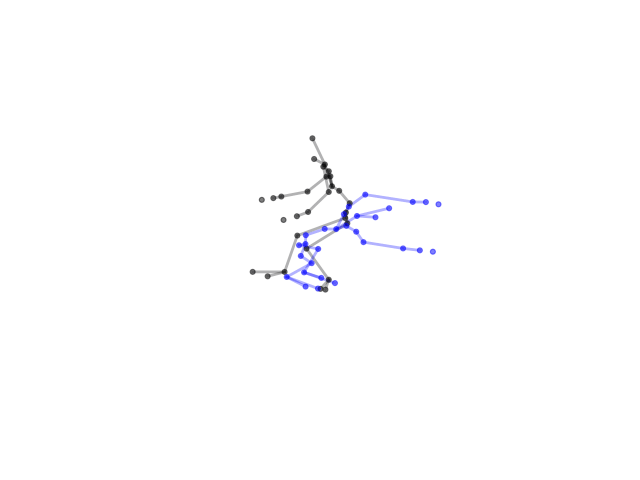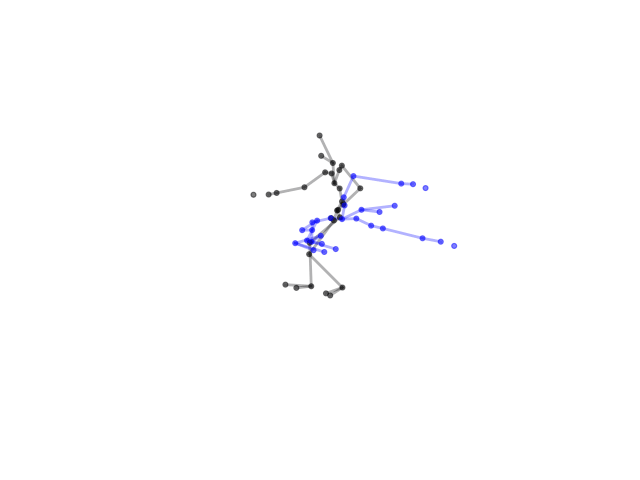
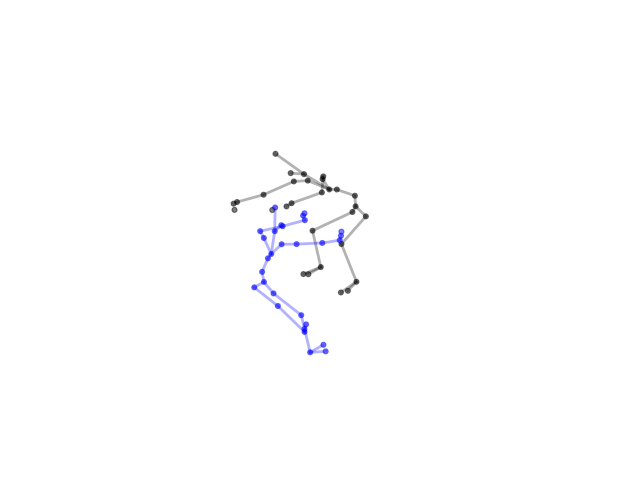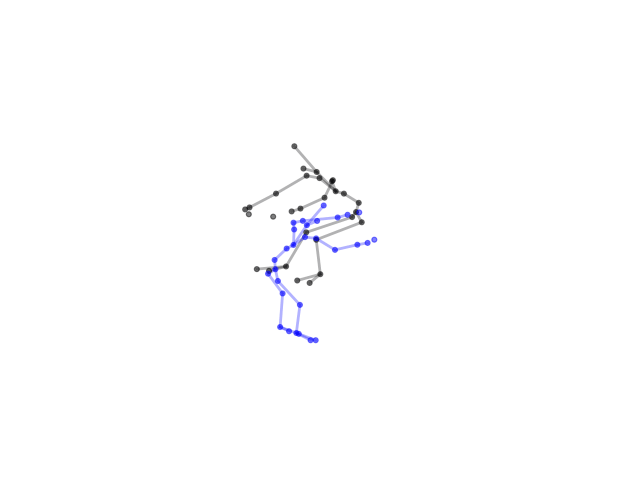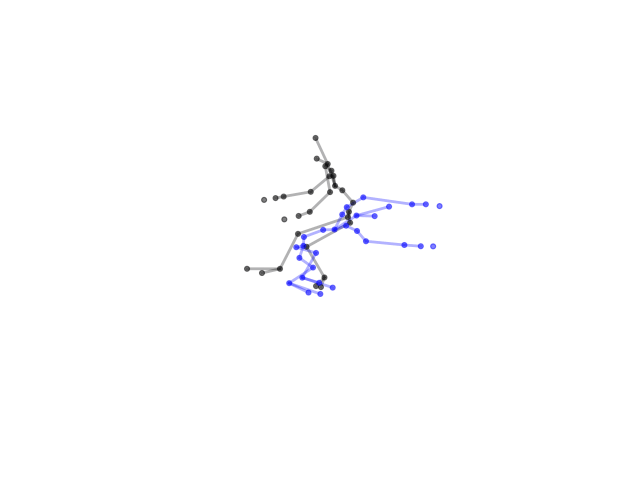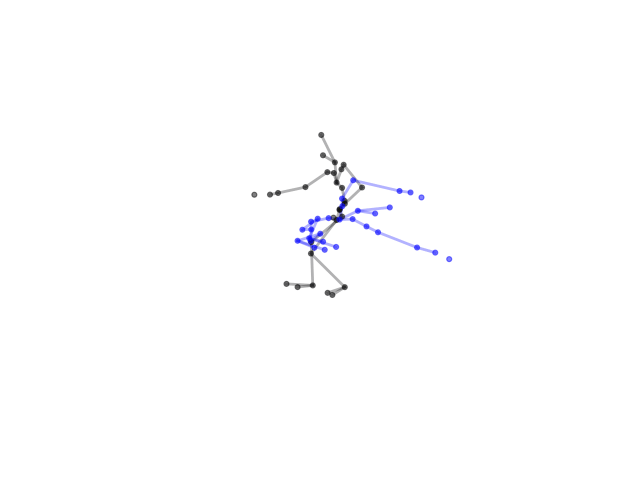

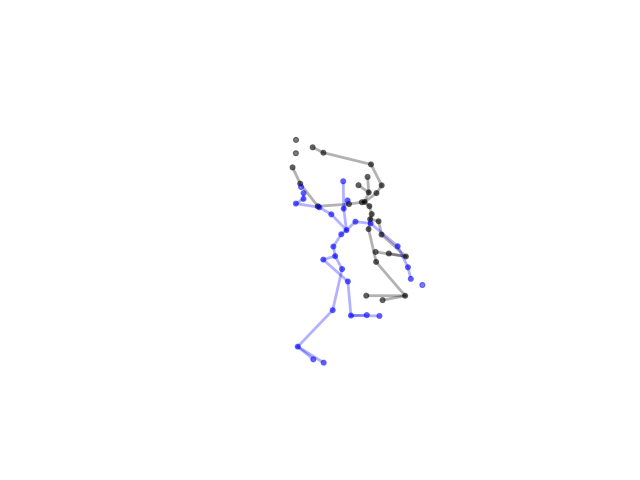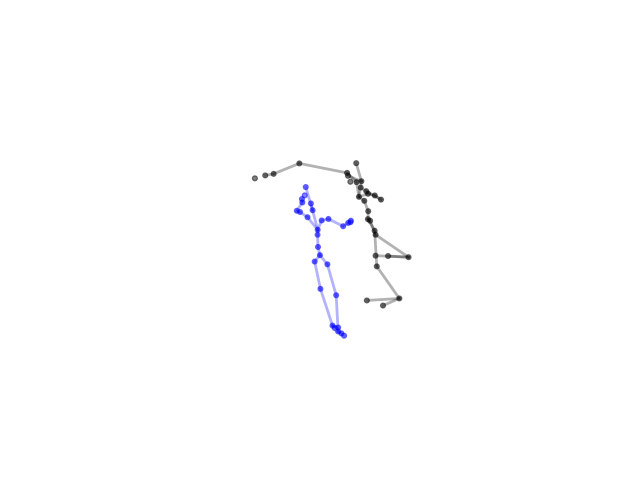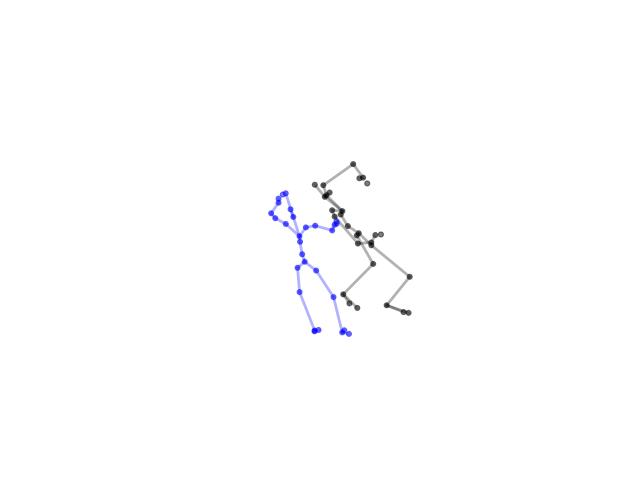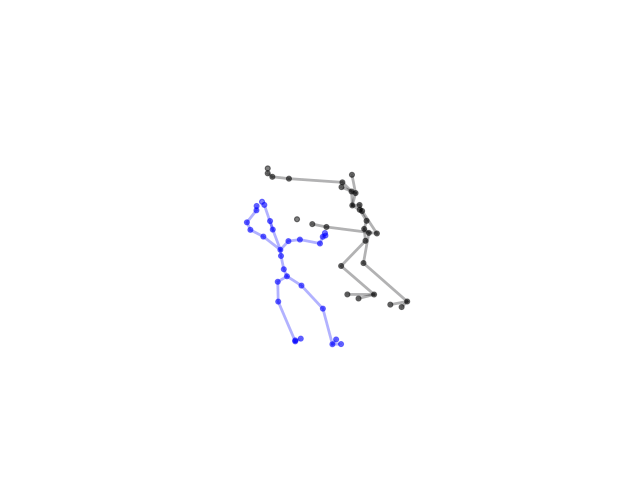
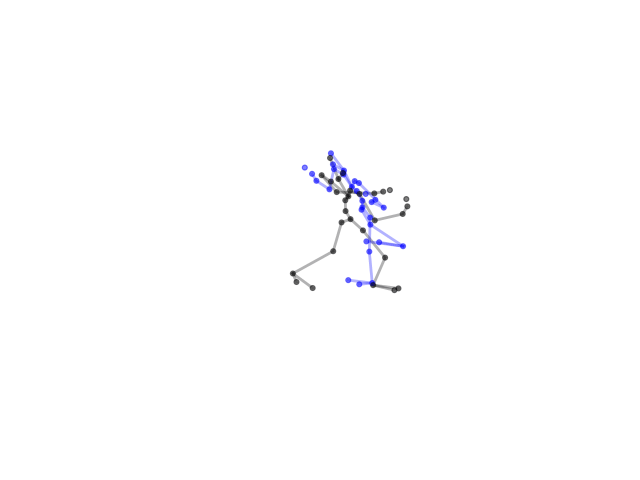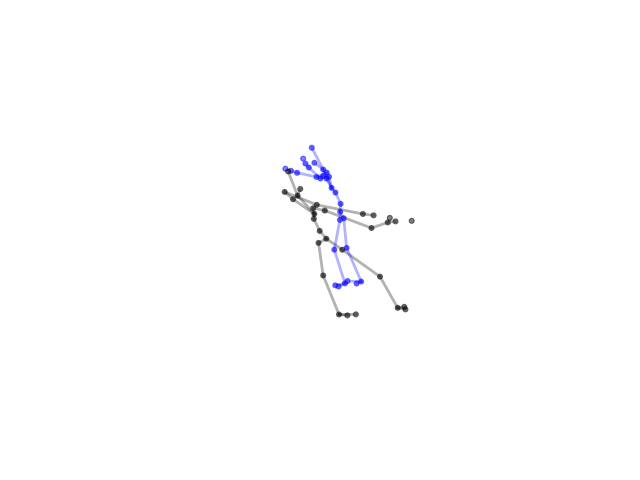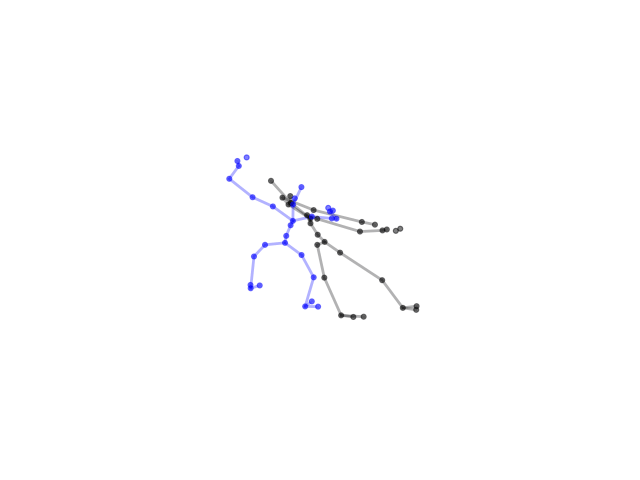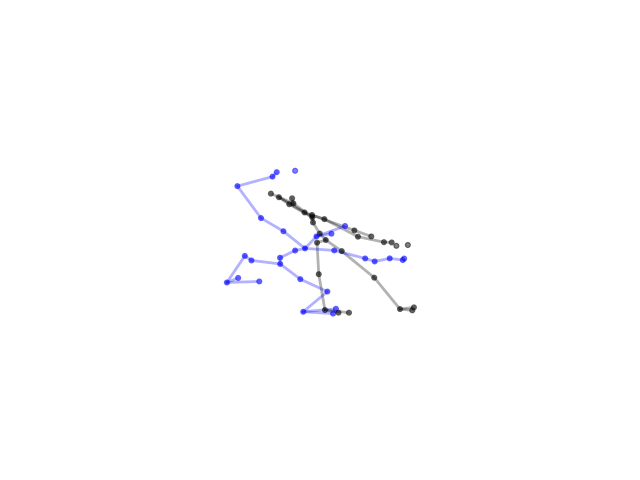
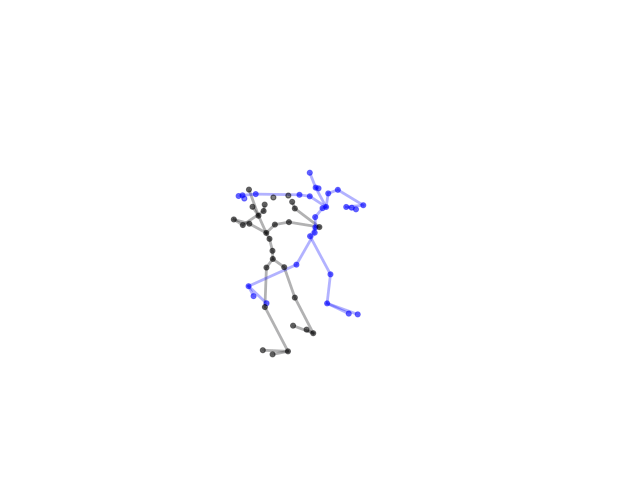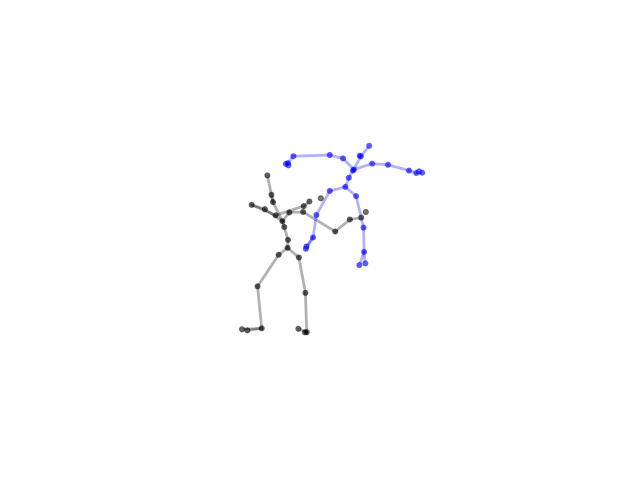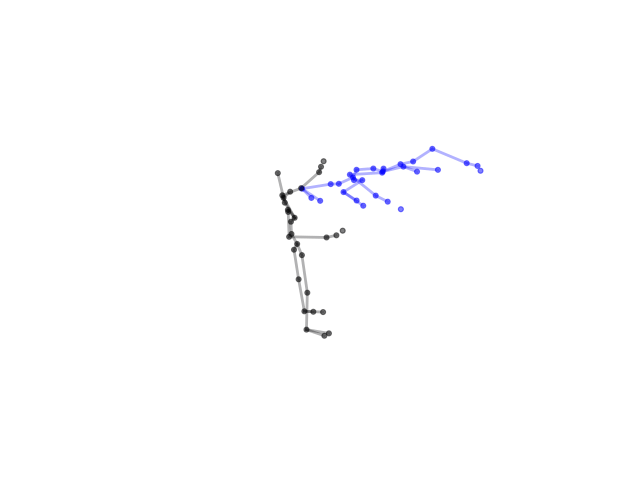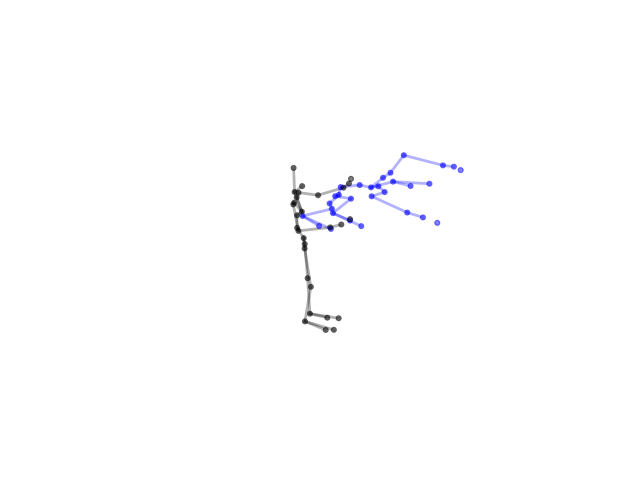
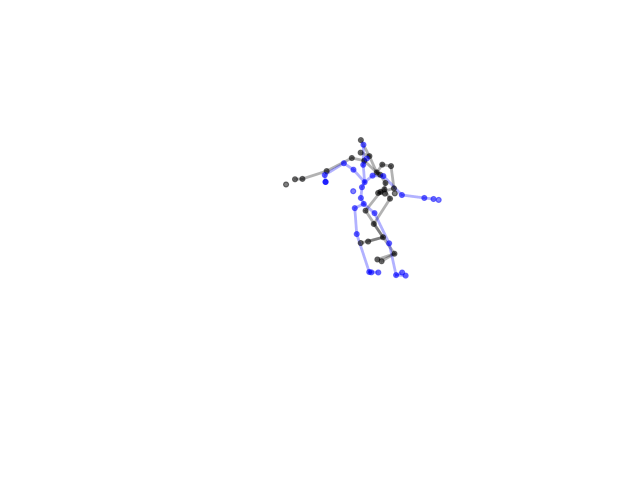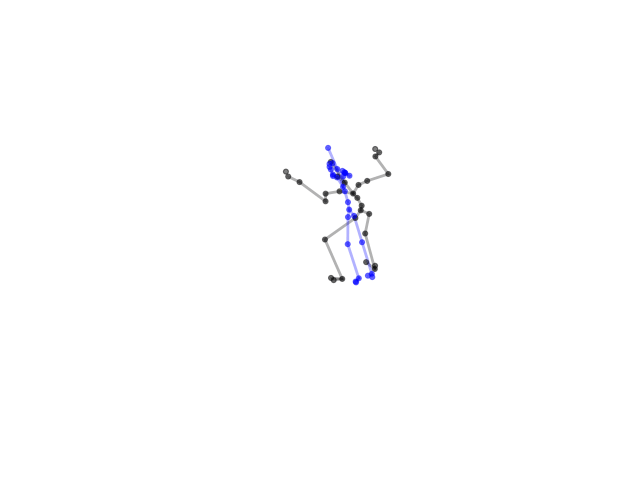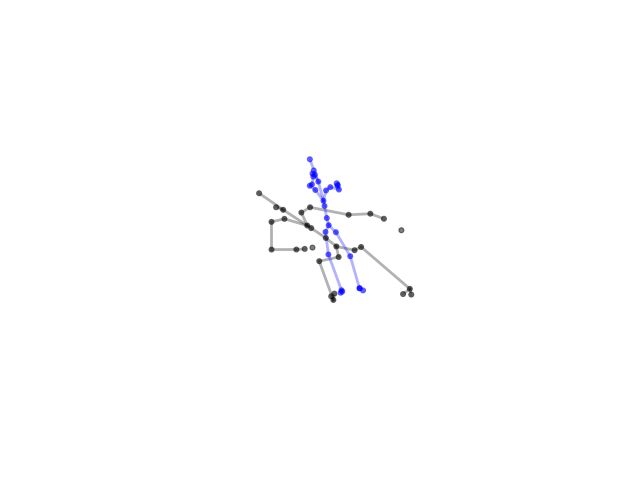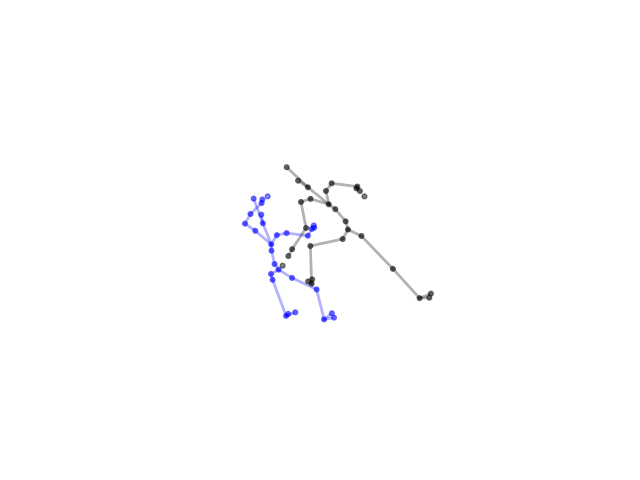
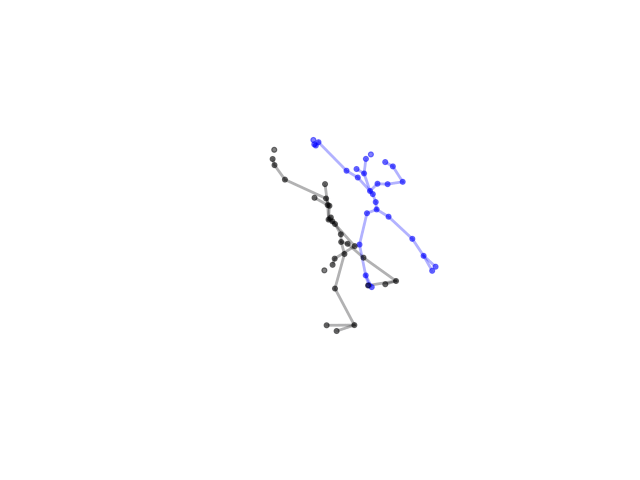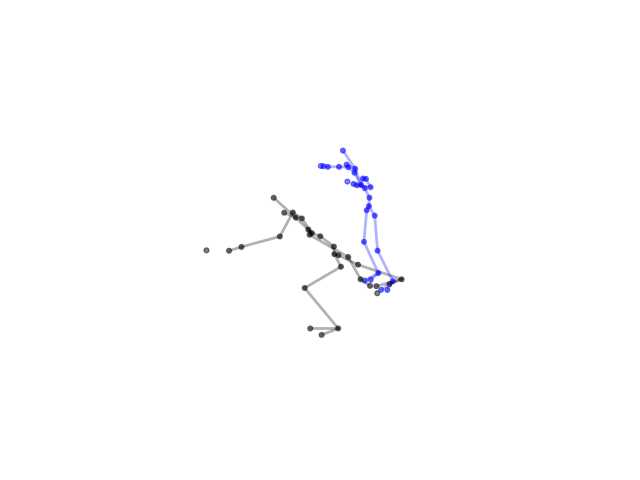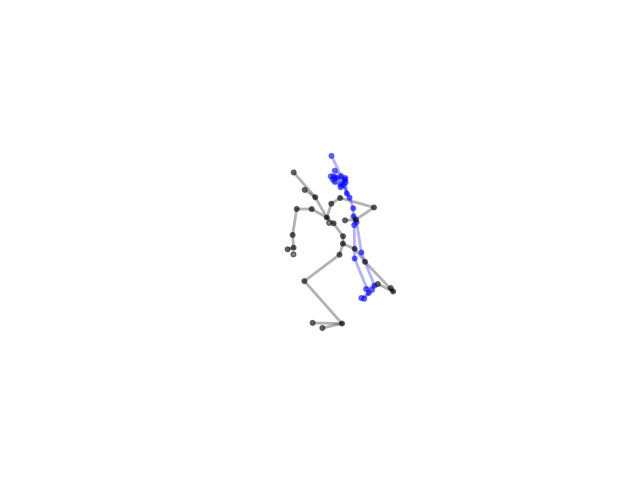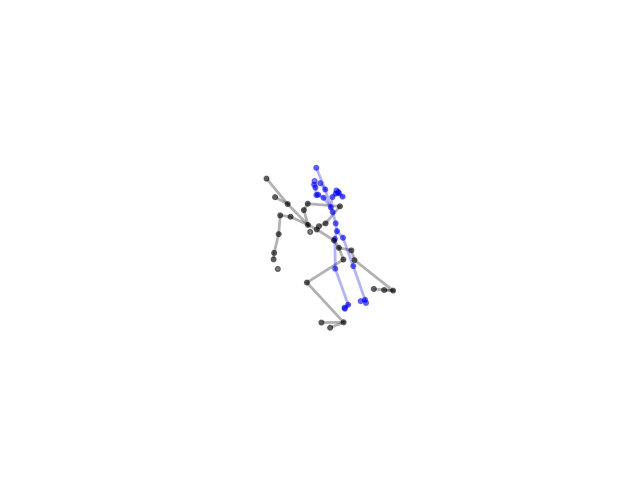
Future Work
- Data Augmentation: Since the amount of data is limited in our project, implementing advanced data augmentation strategies, such as geometric transformations and noise injection will greatly enhance the robustness of the model against variations in dance styles.
- Real-time Choreography Generation: Develop a system for real-time dance choreography generation, allowing dancers to interact with the AI in live performances. This involves reducing latency and improving the computational efficiency of the model.
- Accessible Tools for Choreographers: Design and develop a user-friendly interface that allows choreographers and dancers to easily interact with the technology, modify outputs, and integrate AI-generated choreographies into their creative process.
Acknowledgements
Participating in Google Summer of Code 2024 with HumanAI has been an incredible journey. I am deeply grateful for the opportunity to work alongside brilliant minds and contribute to the field of AI-driven choreography.
Finally, I appreciate the Google Summer of Code program for facilitating this enriching experience and to everyone who supported and followed our progress. This project not only advanced my skills but also contributed to the broader dialogue on how technology can intersect with and enhance the creative arts.